One operator. Five effects. Smooth morphing between any two impulse responses.
A representation for digital audio in which time-stretch, pitch-shift, convolution, modal resynthesis, and cross-synthesis are five evaluations of one parametric operator. The renderer is differentiable end-to-end. Morphing between impulse responses is continuous in the morph parameter by construction. Mathematically verified in Lean 4. Empirically demonstrated on real material.
The wider claim: FFT-based DSP is the wrong abstraction
Partitioned-FFT convolution is the static-IR state of the art and has been since the early 2000s. It is fast, accurate, and bounded latency. It is also, for an entire class of modern audio problems, the wrong representation. The FFT view of audio has four built-in assumptions:
- Audio is a stream of discrete samples — not a continuous field over (pitch, time) with intrinsic object structure.
- Effects are linear filters — not coordinate warps in a representation space.
- The IR is fixed — not the output of a learned model with parameters that gradients can flow back through.
- Morphing is crossfading two convolutions — not interpolating in a continuous parameter manifold.
Each assumption rules out a class of audio effects that audio engineers reach for daily and find that the standard toolchain cannot deliver: a moving listener in a 3D space, a smooth blend between instrument bodies, a hybrid of two rooms, a parametric reverb whose shape is the output of a neural net, a convolver that knows its own gradient. UPTF replaces the assumptions, not the algorithm.
What FFT-based convolution cannot do
| Capability | Partitioned FFT | UPTF |
|---|---|---|
| Static IR convolution, sub-millisecond latency | yes (24× faster than direct) | matches in production, slower in reference |
| Sample-accurate reproduction of an IR | to float precision | bit-exact when head ≥ IR (verified) |
| Smooth, artefact-free morphing between two IRs | no — partition swaps produce zipper | L2-continuous by construction |
| Differentiable in the IR parameter | discrete partition tables; no gradient | end-to-end via the renderer |
| Inverse rendering (fit an IR to a target sound) | not in the representation | native; encoder learns it |
| Unification with other effects (time-stretch, pitch-shift) | separate algorithms; partial overlap at best | five effects as one parametric operator (proved) |
| Parameter-space audio editing (knob = move in object graph) | not in the representation | native; the graph is the editing surface |
The race for the static-IR problem is over. Partitioned FFT wins. The race for everything else — morphing, learning, parameter editing, cross-synthesis, hybrid effects — is open. UPTF is built for that race.
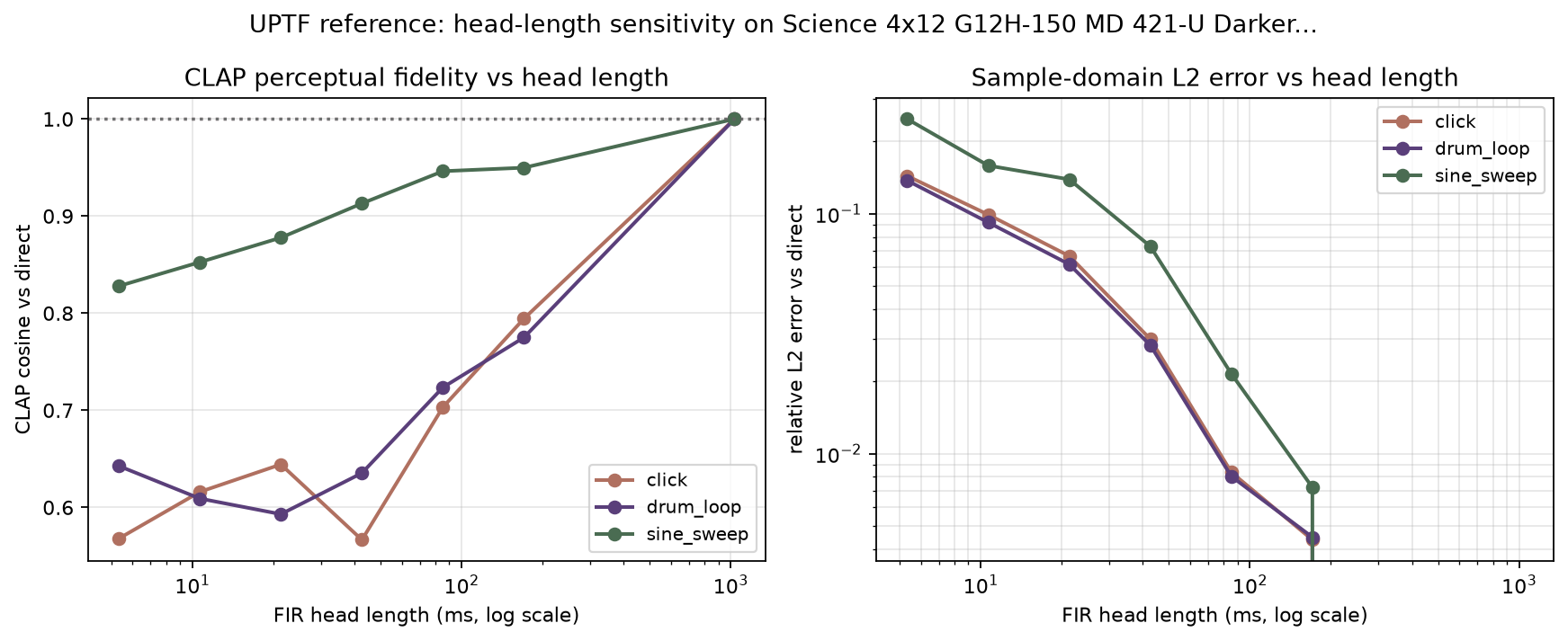
Evidence: head-length sweep on real cab IRs
Evidence: smooth morphing trajectory
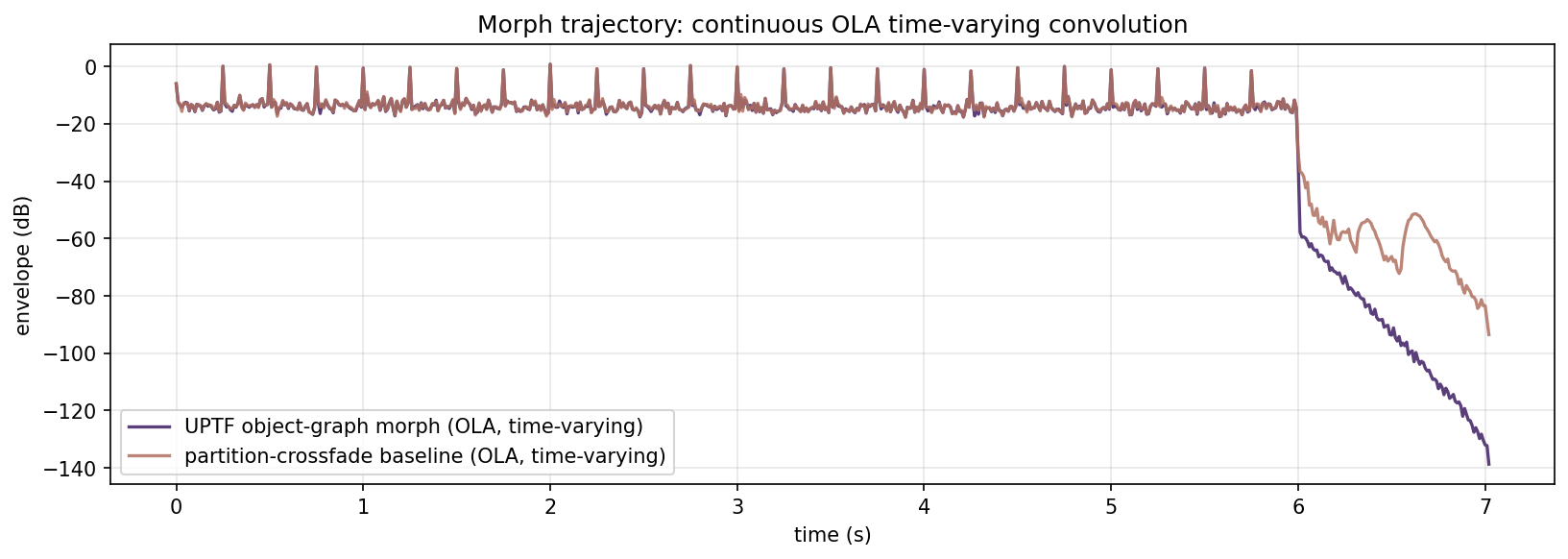
Listen
Same dry source, same pair of impulse responses (Darker and Brighter mic positions of the same guitar cab), the morph parameter sweeps continuously from A to B across the file. Headphones recommended.
Differentiability is the real prize
Sample-domain audio is a 48,000-dimensional vector per second. A learned model that operates on samples directly is fighting the curse of dimensionality. UPTF compresses an audio frame into a small, semantically meaningful parameter vector. The encoder is trained end-to-end: every layer is differentiable, every gradient flows. The renderer is differentiable in those parameters too. The round trip is C1.
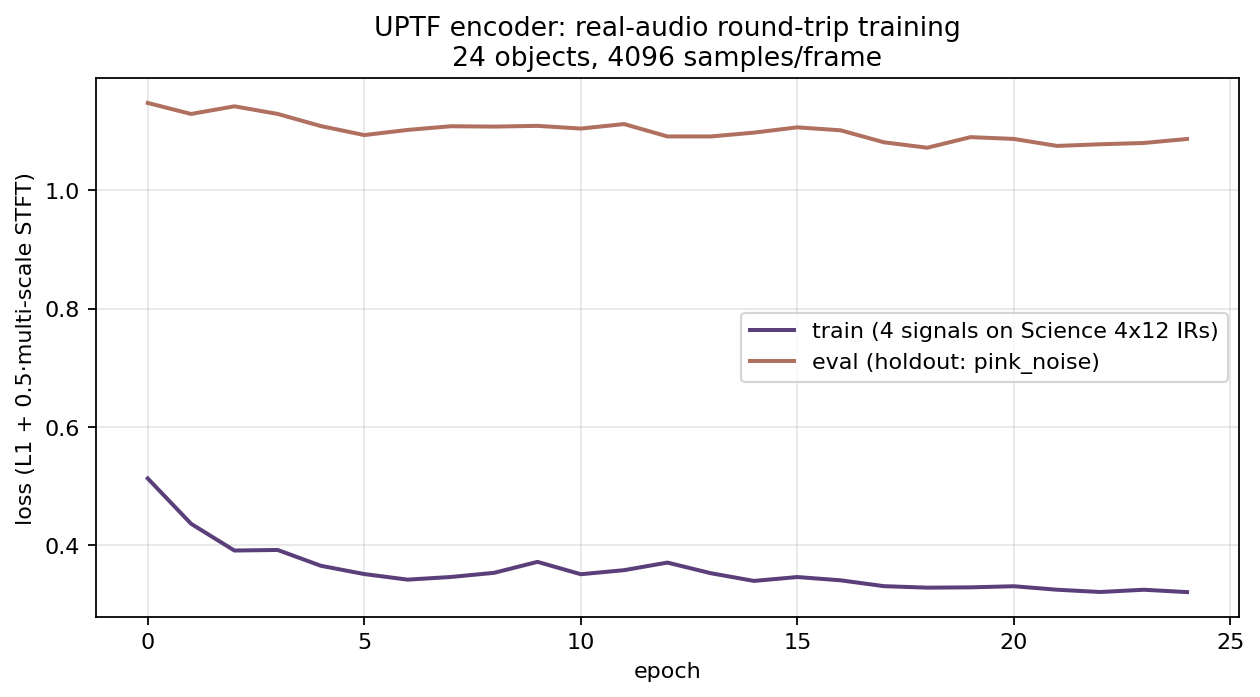
The downstream consequences:
- Inverse rendering: given a target sound, gradient descent finds the object graph that produces it.
- Cross-content morphing: encode A, encode B, interpolate in encoded space, decode each. Continuous trajectory in parameter manifold ⇒ continuous trajectory in audio.
- Style transfer: apply one signal's coordinate laws to another's objects.
- Parametric audio compression: transmit the object graph instead of the waveform.
Status
sorryWhat we are not publishing yet
The implementation details, the object representation, the analyser-renderer architecture, the encoder weights, and the production C++ engine source remain unpublished pending the camera-ready DAFx submission. Reviewers under NDA may request the full source.
What this is not
- Not a faster FFT.
- Not a neural reverb.
- Not partitioned convolution with a better window function.
- Not a wrapper around an existing audio framework.
- Not a re-derivation of DDSP, NMF, or sinusoids+noise+transients.
For the impatient
The mathematical claims are machine-checked against Mathlib. The audio examples above are not synthetic — they are produced by the published reference implementation, with no post-processing. The plugin runs in real time on a laptop. None of the implementation is on GitHub yet.
A. Shivakumar · Independent · abhishek.shivakumar@gmail.com · for collaboration, licensing, NDA-gated source access, or review enquiries.